How it Works - Quick Intro
Sample YAML file configurations
Please visit this page for a list of the most common use cases and configurations in Squash.
How It Works
Squash works by creating unique testing URLs for each branch of code. This is by default integrated with Pull Requests (or Merge Requests in GitLab) in your favorite hosted version control system: GitHub, Bitbucket or GitLab. When you create a new Pull Request Squash will automatically post a comment like this:

The Squash comment above can be customized to support multiple applications, subdomains and to also include specific URL paths and query strings.
You can also manually generate deployment URLs from the Squash Web Interface:
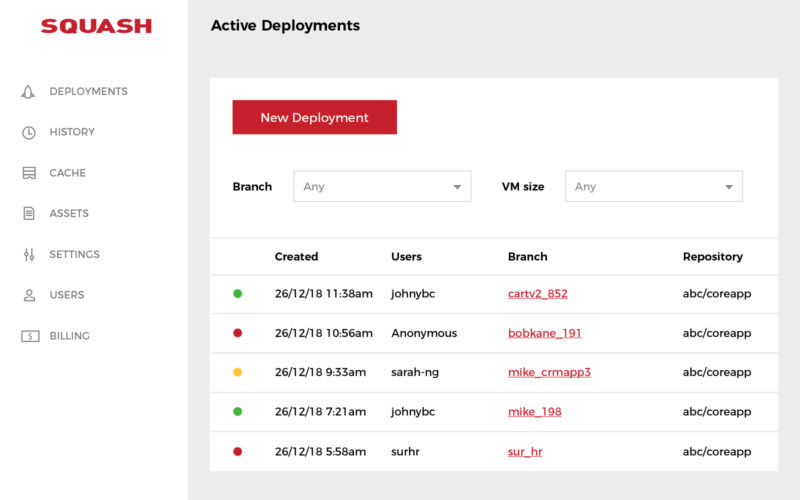
The application build process
Squash was designed from the ground up to support complex web applications and microservices. Any web applications that can run in a Linux machine will run on Squash.
We support Docker & Docker-compose, Kubernetes and apps without Docker, through the Squash YAML file.
You can run clusters with multiple containers/microservices in one Squash VM, or within a group of separate VMs within a deployment dependencies chain.
How a Squash URL works
When you click on the URL for the first time Squash will immediately start deploying it. In this case you will see a loading page like this (more info on the visibility of the loading page and logs):
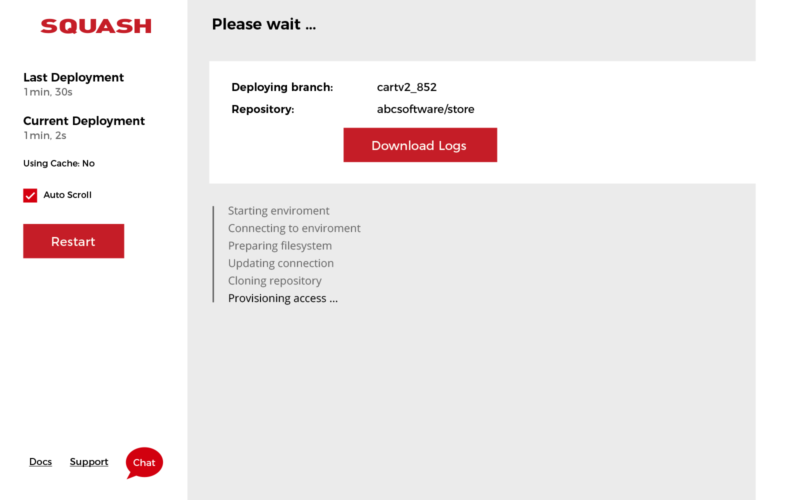
Behind the scenes Squash is creating a brand new virtual machine, pulling your branch of code and building it from scratch (or also using a Deployment Cache if available).
Then once your application starts responding with a successful HTTP response Squash will automatically route all requests to your app and you will start seeing it from that same URL, like this:
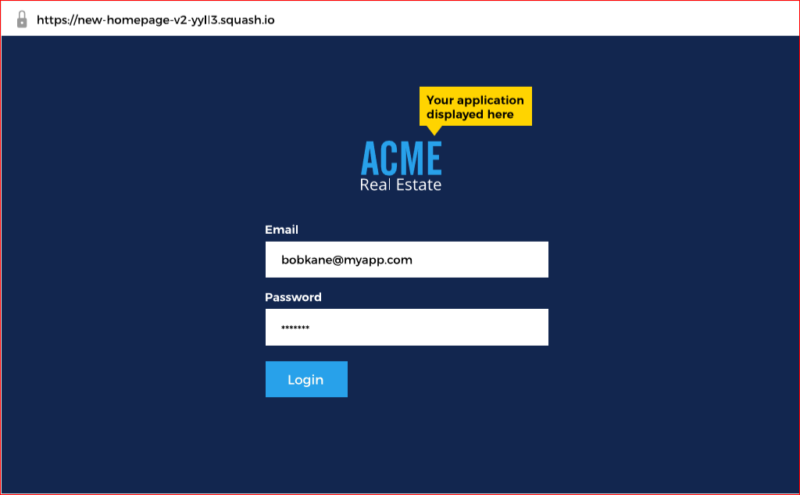
Deployment URL life cycle
Your application will continue to work off this same URL according to its auto shutdown policy, you have lot's of flexibility to control for how long you want these environments to live. Squash takes care of eliminating server waste, making sure your environments are available only when you need them.
What happens when a deployment URL expires
After the deployment's expire time is reached, that environment will automatically be decommissioned. But don't worry, next time you click on the same deployment URL, if the deployment is no longer available, Squash will automatically start it again.
Sometimes you may also enable persistent storage to keep all your data intact between runs.
I have one app made of several microservices, each microservice is on its own repository
This is a fairly common use case, and yes it's supported by Squash. Refer to One app and multiple repositories (Multi-repo applications).
Want to know more? checkout our list of features.