Deployment Dependencies
This feature is currently not available for accounts under the free plan. For more details please go to our plans page.
Squash supports linking apps/microservices from multiple code repositories. This facilitates the deployment of complex apps with multiple microservices living in separate repositories. You may also define dependencies such as a database service running on its own VM or any type of non-HTTP services as dependencies.
You can use this feature with repositories based on Docker/docker-compose, and also for repos without Docker. Squash also makes it easy to automatically link matching branches between dependencies. For instance, you may define a parent deployment running on branch "abc" and have Squash automatically deploy dependencies matching the same "abc" branch, when the branch is available on each dependent repo (more info and examples below).
How it works
- Define the dependency chain using the "depends_on" field within the Squash YAML file, for the desired repositories.
- Each dependency triggers its own deployment/VM on Squash. This has several benefits:
- Each dependency is started in parallel making the entire dependency chain start faster.
- Optimal server resources isolation for each dependency/microservice, avoiding issues where services compete with each other causing potential QA bottlenecks.
- You can easily debug and detect issues on specific services
- Squash supports one-to-one, one-to-many and multiple levels of dependencies (see examples below).
- Easy way to start and restart each dependency as well as restarting or stoping the entire dependency chain at once.
- You may leave one or more deployments running and then attach multiple new deployments to existing running deployments. For instance:
- You may have an API service that doesn't change often and that has some useful data in the database
- You can leave the API service running for as long as needed and use it with as many branch specific deployments as needed.
- You can also reduce server waste by using auto shutdown policies. Even when the API service is down Squash will automatically start it as part of a dependency chain.
Here is a quick example of how to define a dependency chain, for this example we have an "eCommerceApp" with two dependencies, the "Sales API" and "Products API". Both dependencies are separate services running within their own virtual machines.
deployments:
eCommerceApp:
filename:
./src/myapp/Dockerfile
vm_size:
1GB
depends_on:
- SALES_API:
app: api-sales/master
- PRODUCTS_API:
app: api-products
- For the example above, SALES_API and PRODUCTS_API are also names of environment variables that will be set in the eCommerceApp deployment with a reference to each service's endpoint. This is how you can communicate deployments with each other (more info below).
- "api-sales" and "api-products" are repository names.
Communication/link between dependencies
The way each deployment on a dependency chain communicates with each other is by using environment variables.
Child deployments:
- Squash automatically sets a SQUASH_MASTER_DEPLOYMENT environment variable on each child deployment with the exact end point of the master deployment. This environment variable is set right after the master deployment receives a success response.
- The content of the SQUASH_MASTER_DEPLOYMENT env variable will look like this:
SQUASH_MASTER_DEPLOYMENT=//js-refactor-am1y7.squash.io
Master deployments:
- Squash automatically sets a new environment variable on each master/parent deployment with the exact end point of each child deployment. These environment variables are set right after each child receives a success response.
- The name of each environment variable is defined within the Squash YAML file.
- The content of each env variable will look like this, where "EXAMPLE_SERVICE" was explicitly defined in the Squash YAML file:
EXAMPLE_SERVICE=//js-refactor-a1w8z.squash.io
Example:
For this example we are using a basic scenario with a one-to-one relationship:
- eCommerceApp: this is the actual repository that holds the YAML file below
- API service that supplies product data to the eCommerce application. This API service is defined in a different repository. Repository name: "api-products".
Squash YAML file:
deployments:
eCommerceApp:
filename:
./src/myapp/Dockerfile
depends_on:
- PRODUCTS_API:
app: api-products
For the example above, the eCommerce app deployment will contain the following environment variable:
PRODUCTS_API=//js-refactor-a1w8z.squash.io
And the deployment associated with "api-products" will have an environment variable similar to this:
SQUASH_MASTER_DEPLOYMENT=//js-refactor-am1y7.squash.io
Managing dependencies in the Squash UI
You can easily view and manage the entire dependency chain from the Squash UI, allowing you to restart specific dependencies and SSH to each VM for debugging purposes.
When loading a deployment with dependencies Squash displays right away, during its build process, each dependent deployment and their own build status:
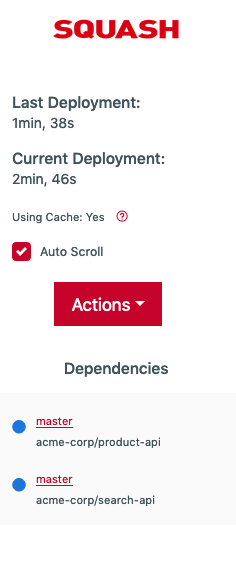
This is how a 3 step (one parent and 2 dependencies) deployment looks like in the Squash dashboard. Note the parent deployment at the bottom and its two dependencies above. These deployments are all off branch "master".
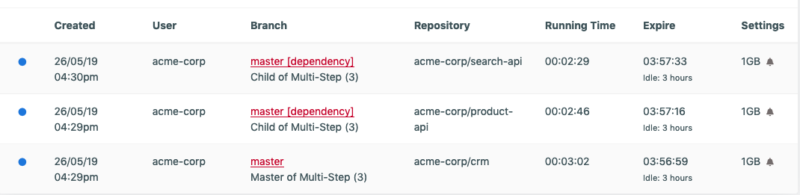
And when you open each deployment on a dependency chain you can see the other associated deployments within the chain:
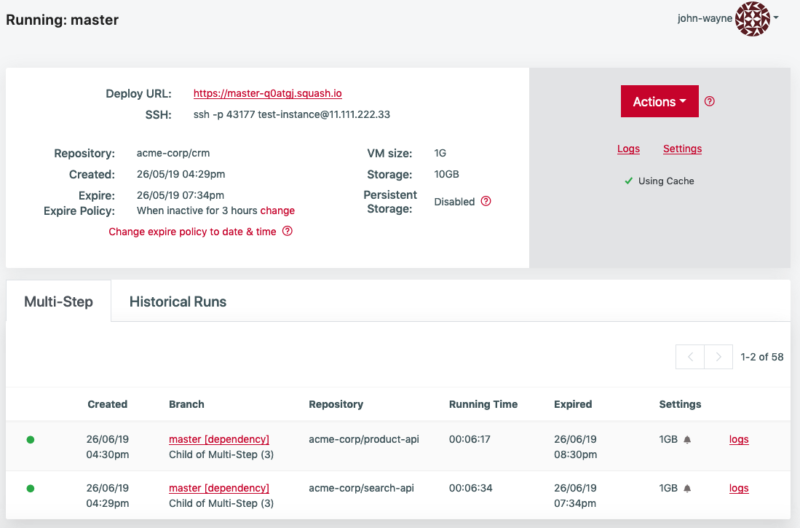
Please note that the "Multi-Step" tab is not visible for regular deployments without dependencies. This tab is also not visible to child deployments that don't have any dependencies.
Stop/Restart of deployments with dependencies
You may also restart or stop the entire dependency chain at once:
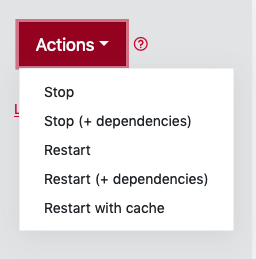
The following restart options are only visible to deployments with one or more dependencies:
- Stop (+ dependencies)
- Restart (+ dependencies)
What happens when a given deployment within a dependency chain is already running
- Let's use for example the following deployment chain:
- CRM App
- api-products
- api-search
- CRM App
- In the example above we have a parent (CRM App) with two children (api-products and api-search).
- When we start the CRM App deployment Squash will automatically deploy api-products and api-search.
- However, if any of the dependencies are already running Squash will automatically attempt to attach them to the new parent. Squash supports multiple parent deployments connected to the same child/children.
Linking to multiple services within the same VM
You can assign multiple service ports to specific subdomains and then include these in the deployment chain.
For instance, let's use this example API service, it's a docker-compose based deployment with 2 microservices. Note that we are mapping each microservice with a subdomain, using subdomain port mapping:
deployments:
APIs:
filename:
./src/docker-compose.yml
subdomain_port_mapping:
- products:3000
- sales:8080
We want to add map the "products" microservice above as a dependency of an eCommerceApp deployment. This is how this would look like. Note that "acme-apis" is a repository name that holds the Squash YAML file defined above, in the "APIs" application.
deployments:
eCommerceApp:
filename:
./src/Dockerfile
depends_on:
- DATA_PRODUCTS_API:
app: acme-apis
subdomain: products
When we start the deployment above the eCommerceApp will automatically have an environment variable as follows:
DATA_PRODUCTS_API=https://products--branch-name-i3xg7.squash.io
YAML file example #1
The examples below will illustrate different scenarios using the Squash depends_on field to define dependencies within the YAML file.
For this example we are using the most basic scenario with a one-to-one relationship:
- A web app for a hypothetical CRM application.
- API service that supplies product data to the CRM application. This API service is defined in a different repository. Repository name: "api-products".
Squash YAML file:
deployments:
CRM:
filename:
./src/myapp/Dockerfile
depends_on:
- PRODUCTS_API:
app: api-products
YAML file example #2
Here we are using a database service as a dependency, for more details please check Non-HTTP based deployments.
deployments:
MyApp:
filename:
./src/docker-compose.yml
port_forwarding: 80:8069
depends_on:
- POSTGRESQL:
app: my-repo/master:postgres
postgres:
dockerimage: postgres:9.4
run_options: -e POSTGRES_PASSWORD=passwd -e POSTGRES_USER=user
check_service_ports: 5432
port_forwarding: 5432:5432
YAML file example #3
This example shows a one-to-many relationship, with 3 repositories:
- "crm" repository: A web app for a hypothetical CRM application. This is the actual repository that holds the first YAML file defined below. This repo depends on repositories "api-products" and "api-search".
- "api-products" repository.
- "api-search" repository.
Squash YAML file:
deployments:
CRM:
filename:
./src/myapp/Dockerfile
depends_on:
- PRODUCTS_API:
app: api-products
- SEARCH_API:
app: api-search
For the example above we are not defining any branch names within each dependency. Squash will automatically fetch the same branch of the parent repo, if available on each dependent repository. If a matching branch doesn't exist Squash will use the default branch (such as branch "master") on the respective repository.
Let's illustrate this process step by step:
- Let's assume we are about to test a branch named "app_v2" in the parent repository (the repo that holds the YAML file below and that defines the CRM app).
- When we start this deployment Squash will first look for branches with the name "app_v2" on both repositories "api-products" and "api-search". If these branches are available Squash will automatically start deployments for these branches.
- Otherwise Squash will deploy whatever default branch is defined on each child repository (branch "master" in most cases).
You may also define specific branches on each dependency to fit your needs. For this example below Squash will only use branch master for the child repository "api-products" (and therefore it will never attempt to use the same branch as the parent repo):
deployments:
CRM:
filename:
./src/myapp/Dockerfile
depends_on:
- PRODUCTS_API:
app: api-products/master
- SEARCH_API:
app: api-search
And for this next example Squash will only use a specific application named "App2" on repository "api-search":
deployments:
CRM:
filename:
./src/myapp/Dockerfile
depends_on:
- PRODUCTS_API:
app: api-products/master
- SEARCH_API:
app: api-search:App2
Lastly, you can get even more specific and restrict dependencies down to a repository, branch and application name, this is what we did for repo "api-products":
deployments:
CRM:
filename:
./src/myapp/Dockerfile
depends_on:
- PRODUCTS_API:
app: api-products/master:App2
- SEARCH_API:
app: api-search
More details on specifying multiple applications in a single Squash YAML file.
YAML file example #4
This example shows a multi level relationship, with 3 repositories:
- "crm" repository: A web app for a hypothetical CRM application. This is the actual repository that holds the first YAML file defined below. This depends on the "api-products" repository
- "api-products" repository. This depends on "api-search" repository
- "api-search" repository
Squash YAML file:
"eCommerce" repository:
deployments:
eCommerceApp:
filename:
./src/myapp/Dockerfile
depends_on:
- PRODUCTS_API:
app: api-products
"api-products" repository:
deployments:
Products:
filename:
./src/myapp/Dockerfile
depends_on:
- SEARCH_API:
app: api-search